OS: Memory Management & Virtual Memory
操作系统内存管理
分配与管理
连续分配
- 单一连续分配 系统被分为系统区和用户区,同时只能由一道用户程序,其独占整用户区空间。
- 固定分区分配 类似上面的单一连续分配,只不过划分成了固定数量的几个分区。
- 动态分配
不预先划分内存分区,而是在进程装入内存时,按照进程的大小动态地建立分区。
使用两种常见的数据结构实现
- 空闲分区表: 每个表项中包含分区号、大小、起始地址等信息
- 空闲分区链: 每个分区的起始部分和末尾分别设置双向的指针
碎片的概念
- 内部碎片:分配给了进程,但进程没有利用
- 外部碎片:剩余的没有被分配的连续空间太小,难以被利用
动态分区算法
- First Fit
- Best Fit
- Worst Fit
- Next Fit
非连续分配
分页存储
将内存分为大小相等的 page,并进行从 0 开始的编号。
页表
| 页号 | 块号 |
|---|---|
| 0 | 3 |
| 1 | 6 |
| … | … |
页表项的大小:round up 到整数倍字节(存放块号),页号不占空间,因为页表是个数组, 其下标就是页号。
注*:此处页表中字段不完整,完整的页表字段应包含:
- resident 1 bit 标志着是否缺页
- dirty 1 bit 标志着内存中的页与硬盘上的是否相同
- physical page number 物理地址
其中没有逻辑地址是因为逻辑地址隐含在 index 中。
地址转换
对给定的逻辑地址 A
- 确定逻辑地址 A 对应的页号 P(判断 P 是否越界,如果是,则抛出页错误中断)
- 找到 P 号页面在内存中的起始地址(查页表得到页框号,在乘上页大小)
- 确定逻辑地址 A 在页内的偏移量 W(看 A 的最后 n 位即可,n 取决于页面长度)
- 则 A 的物理地址 = P 起始地址 + W
引入快表 TLB 后的分页存储
TLB, translation lookaside buffer 是一种速度比内存快很多的高速缓存, 用来存放最近访问的页表项的副本,可以加速地址转换的速度。 在进程切换时,快表会被清空。
在查询页表前先访问 TLB,如果命中,则可直接获得物理地址,不需要查询页表。
这个地方容易出让算时间的题,注意有的系统支持快表慢表同时查, 计算快表没有命中的时间的方式会稍有不同。
两级页表
单级页表的问题:
- 页表需要连续存储(数组),其占用空间过大(多个连续的页框)。
- 同时高频访问的通常只有个别页面,因此没有必要让整个页表都常住内存。
其中两级页表主要解决了第一个问题,第二个问题由虚拟内存解决。 解决方式:
- 可以将页表进行分组,每个内存块恰好能放入一个分组。
- 为这些离散分配的页表再建立一张页表,称为页目录表或外层页表或顶层页表。
这种模式下的地址转换流程为:
- 按照地址结构将逻辑地址拆分成三部分:一级页号,二级页号,页内偏移量。
- 从 PCB 中读取出页目录表起始地址,再根据一级页号查页目录表,找出下一级页表在 内存中的位置。
- 根据二级页号查表,找到最终想访问的内存块号。
- 结合页内偏移量得到物理地址。
n 级页表的原理类似,从逻辑上可以不断增加页表层数。 如果没有 TLB,n 级页表查询过程中的访存次数是 n + 1 次。
分段存储
进程的地址空间:按照程序自身的逻辑划分为若干个段,每段从 0 开始编址。 所以逻辑地址由段号和段内地址左右两部分组成。
段表:
| 段号 | 段长 | 基址 |
|---|---|---|
| 0 | 7K | 80K |
| 1 | 3K | 120K |
| 2 | 6K | 40K |
其中段号是隐含的数组下标,段表项的大小是段长的大小 + 基址的大小。
地址转换过程:
- 根据逻辑地址得到段号 S 和段内地址 W,判断是否越界。
- 查询段表,得到对应的段表项,检查段内地址是否超过段长。
- 段基址 b + W 即得物理地址。
分段与分页对比
- 每个页大小相同,而段大小不同,需要检查段内地址是否超过段长。
- 页是物理单位,段是逻辑单位。分页对用户是不可见的,而分段需要用户程序显式地 给出段名。
- 分段比分页更容易实现信息的共享和保护。
段页式管理方式
先分段,再分页,每个比页大小大的段都拆成若干个页进行管理。 这种模式下的逻辑地址由三部分组成,从左到右依次为段号,页号,页内偏移量, 实际上就是分段方式下的段内地址按照分页的方式拆分成了页号和页内偏移量。
段页式管理中的段表与段式管理中不同,如下:
| 段号 | 页面长度 | 页表存放块号 |
|---|---|---|
| 0 | 2 | 1 |
| 1 | 1 | … |
| 2 | 2 | … |
其中页表存放块号与页标起始地址一一对应,也就是说一个进程有且只有一个段表, 但可能有多个页表。没有页表寄存器,只有段表寄存器,页表的地址和长度通过 查段表获得。
地址转换流程:
- 根据逻辑地址得到段号、页号、页内偏移量
- 读取段表,判断段号是否越界
- 查段表,找到对应的页表地址和页表长度
- 检查页号是否越界
- 查页表,得到内存块号
- 将内存块号与页内地址相加得到物理地址
虚拟内存
传统内存管理方式的缺点:
- 作业必须一次性装入内存才能开始运行。
- 当大量作业同时运行时,无法容纳所有作业,导致并发性下降。
- 同一时间段内,程序实际上只会访问一小部分内存,而有其他很多不会被 访问到的数据也占用了内存空间。
虚拟内存:
- 基于局部性原理,在程序装入时,将程序中很快会用到的部分装入内存, 将暂时用不到的部分留在外存。
- 在虚拟内存的抽象下,在用户态程序看来似乎有一个比实际内存大得多的内存。
请求分页管理方式
在基本分页的基础上,增加调页功能(将需要的但内存中缺失的页面从外存中调入) 和换页功能(将暂时用不到的页面从内存换出到外存)。
请求分页的页表
| 页号 | 内存块号 | 状态位 | 访问字段 | 修改位 | 外存地址 |
|---|---|---|---|---|---|
| 0 | - | 0 | 0 | 0 | x |
| 1 | b | 1 | 10 | 0 | y |
| 2 | c | 1 | 6 | 1 | z |
- 状态位:是否已调入内存
- 访问字段:记录最近被访问过几次或记录上次访问时间,换页算法用这个做参考
- 修改位:页面调入内存后是否被修改过
- 外存地址:页面在外存中的存放位置
缺页中断机构
当发现页不再内存中时,发起一个缺页中断。
- 如果有空闲内存块,则按照页表中的外存地址将页面加载。
- 如果没有空闲内存块,则需要选择一个页面换出 (如果修改位是 1,则要将其写回外存),再加载当前需要的页。
请求分页在有快表时,如果快表命中,则说明内存中一定有这一页, 当某一页被换出时,也要从快表中删掉对应的快表项。 在对内存页进行操作时,也要及时更新页表项中的字段,并将更新的页表项在快表中同步。 一般只有在需要将快表项删除时才将脏页面写回外存。
换页算法
追求更少的缺页率
- OPT 最佳置换法 每次选择以后永不使用,或在最长时间内不再被访问的页面, 这是一种 oracle 的算法,实际上无法实现。
- FIFO 先入先出。
- LRU 最近最久未使用置换法,性能最接近 OPT,但是开销较大。
- CLOCK 时钟置换法,也称作最近未用算法 NRU 将内存中的页面构建为一个循环队列,当某页被访问时,其访问位设为 1。 当需要淘汰一个页面时,开始循环遍历这个队列,如果访问位是 1,就将其设为 0, 如果访问位是 0,就将其换出。
- 改进型时钟置换法,在上一个算法的基础上,优先淘汰没有被写脏的页。 由于要扫描两个字段而非一个,所以最多扫描 4 轮(上面算法最多扫描 2 轮)。
页面分配策略
驻留集:请求分页管理中给进程分配的物理块的集合,可以固定分配或动态分配。
调入页面
- 预调页,根据局部性原理
- 请求调页
Thrashing 振荡
当程序持续地导致页错误,页被频繁地在内存与硬盘上交换,导致程序本身运行速度降低。 缓解这一现象的方式有
- 预取机制,预测接下来要访问的页,一并换入物理内存,以减少发生缺页异常的次数。
- 设计更好的换页算法。
内核内存的分配
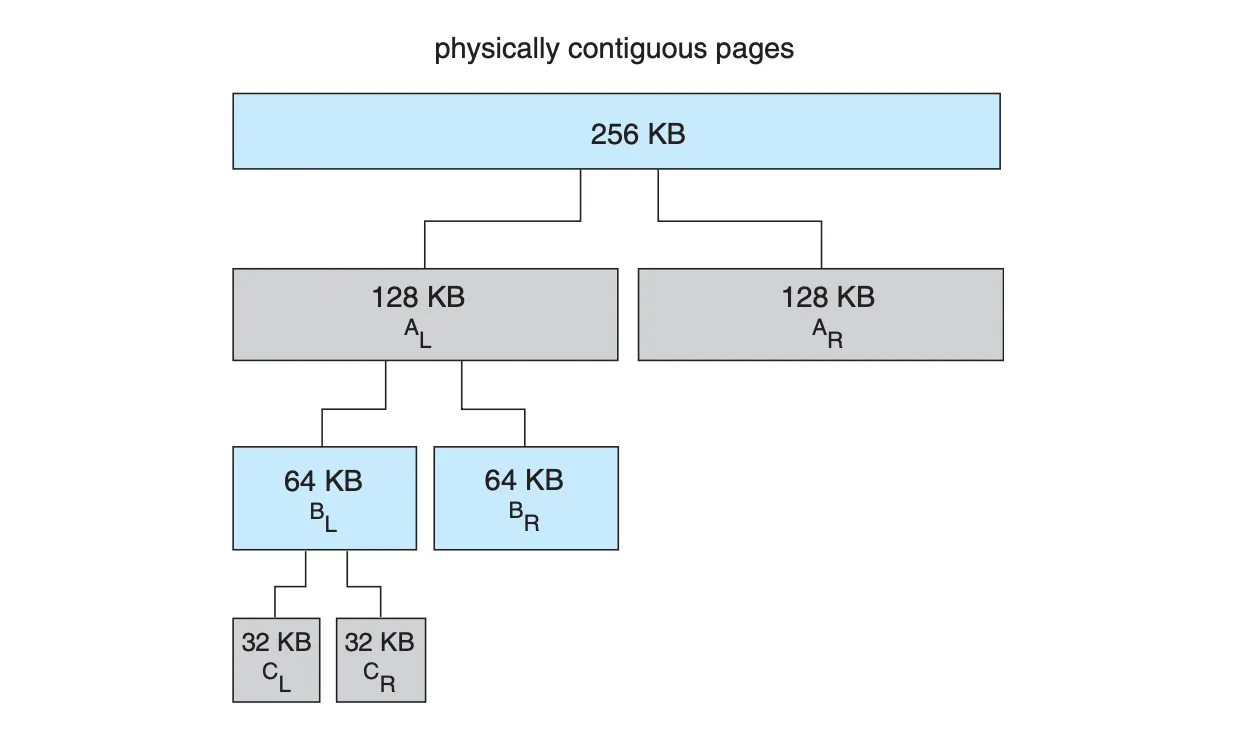
Buddy System
Slab Allocation
基于内核中内存使用的一些特点:
- 一些需要频繁使用的同样大小数据经常在使用后不久又再次被用到
- 找到合适大小的内存所消耗的时间远远大于释放内存所需要的时间
slab 分配方式将申请到的整块内存分为更小的 chunk,并设置缓存。
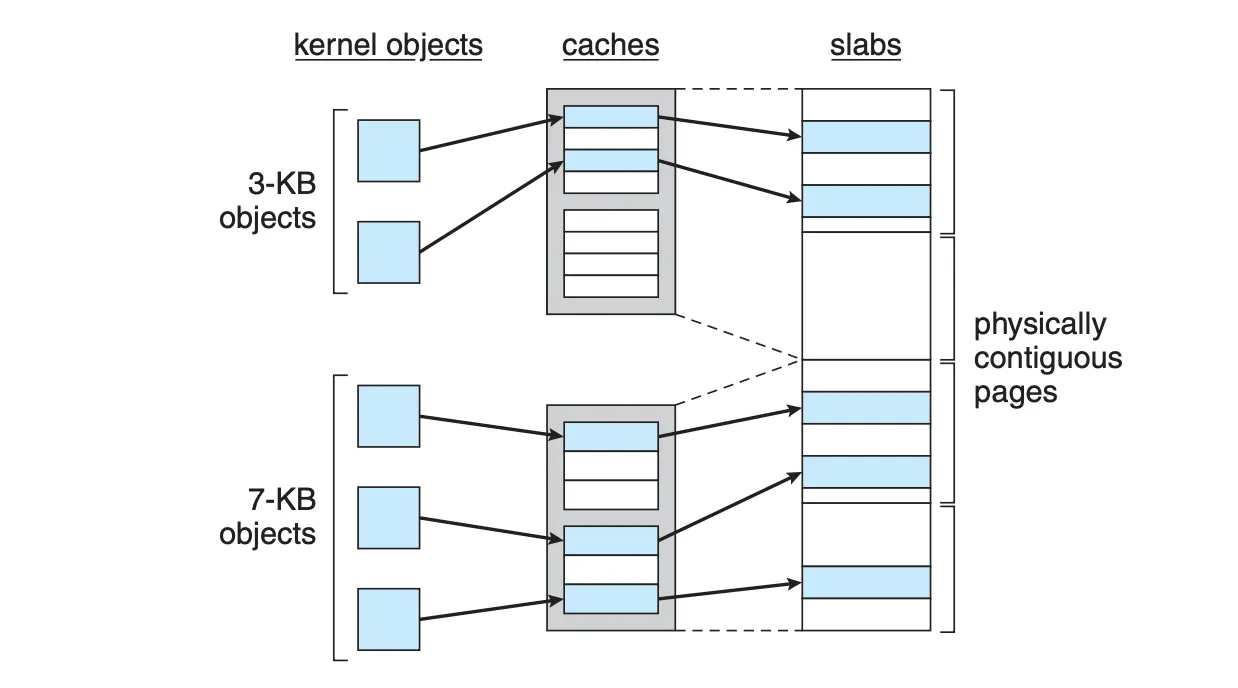
- No memory is wasted due to fragmentation.
- Memory requests can be satisfied quickly.