流水线
第三章
Last updated on
分类
- 部件级、处理机级、系统级
- 单功能与多功能
- 静态与动态
- 线性与非线性
- 顺序与乱序
性能指标
吞吐率
- : 吞吐率,单位时间内流水线所完成的任务数量或输出结果数量
- : 第 段所需时间
各段时间不等的流水线的实际吞吐率为
最大吞吐率为
优化性能
消除瓶颈段
- 细分瓶颈段,使瓶颈段不再是最慢的一段
- 重复设置瓶颈段
加速比
- : 顺序执行所用的时间
- : 按流水线方式处理所用的时间
- : 流水线段数
- : 流水线指令数
理论加速比
实际加速比:若各段时间相同,一条 段流水线完成 个连续任务
这种情况下,最大加速比为
流水线各段时间不等时,实际加速比为
效率
流水线的效率指流水线设备的利用率,实际上就是时空图中阴影面积比总面积。
相关与冲突
举例:MIPS 5 段流水线
- 取指 IF
- 指令译码 / 读寄存器 ID
- 执行 / 有效地址计算 EX
- 存储器访问 / 分支完成 MEM
- 写回 WB
| ALU | Load/Store | Branch | |
| IF | 取指 | ||
| ID | 译码、读寄存器堆 | ||
| EX | 执行 | 计算访存有效地址 | 计算目标地址设置条件码 |
| MEM | 访问存储器 | 若条件成立 转移目标地址送 PC |
|
| WB | 计算结果写回寄存器堆 | Load 数据写回寄存器堆 | |
相关
两条指令之间存在某种依赖关系,在流水线中不能重叠或只能部分重叠。
- 数据相关:后面的指令依赖前面的指令产生的结果,且这种关系可传递。
- 名相关:“名” 指存储器或存储单元名称,名相关是两条指令使用相同的名,
但并没有数据流动。
- 反相关:两条指令所读的名相同
- 输出相关:两条指令所写的名相同
- 控制相关:分支内的指令与条件判读指令之间的相关。
流水线冲突
由于相关存在,流水线中的下一条指令需要延迟执行。
-
结构冲突:硬件满足不了指令重叠执行。
-
数据冲突:需要用到前面指令的结果。
-
写后读:j 用到 i 的计算结果,且在 i 将结果写入寄存器之前 就去读该寄存器,得到旧的值。
-
写后写:指令 j 和指令 i 的结果寄存器相同,且 j 在 i 写入之前 就先对寄存器进行写入,导致写入顺序错误。
-
读后写:j 的目的寄存器和 i 的操作数寄存器相同,且 j 在 i 读取之前就写入了,导致数据错误。
定向(旁路)技术
在发生写后读相关的情况下,在计算结果尚未出来之前,后面等待结果的 指令不一定马上就要用该结果。
如果能将计算结果从其产生的地方(ALU 出口)直接送到其他指令 需要它的地方(ALU 的入口),就可以避免停顿。
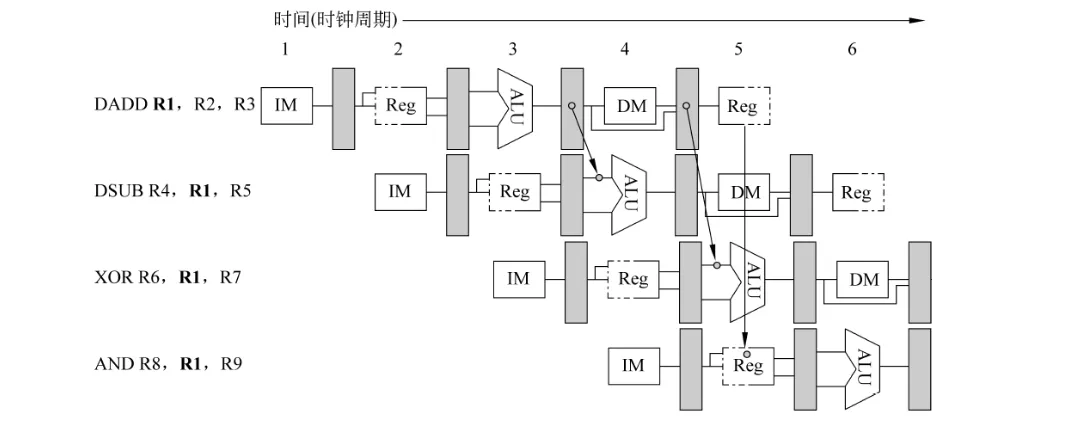
并不是所有数据冲突都能够通过定向技术解决,有时必须停顿。 此外,可以通过在编译阶段进行指令调度的方式减少数据冲突。
-
-
控制冲突:遇到分支指令或其他改变 PC 的指令。分支成功:PC 值改变 为分支转移的目标地址。流水线中,由分支指令引起的延迟称为分支延迟。 为减少分支延迟,可以
- 在流水线中尽早判断(或预测)分支
- 尽早计算分支目标地址
题目
3.6
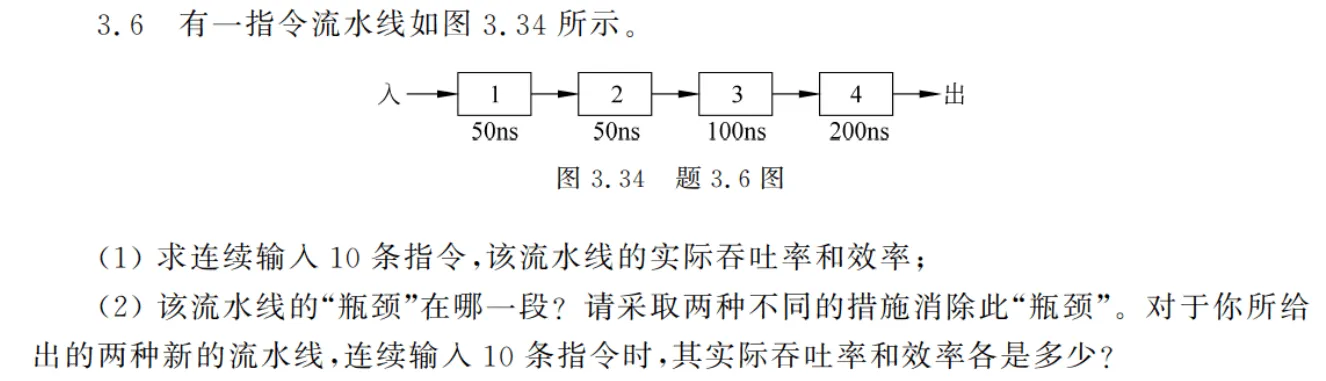
- 实际吞吐率: 效率:
- 瓶颈在用时 100ns 和 200ns 的段,可重复设置瓶颈段或将其拆分来消除瓶颈。
- 采用拆分瓶颈段的方式,将第三段拆分为 50 * 2,第四段拆分为 50 * 4。 此时实际吞吐率 ,效率 。
- 采用重复设置瓶颈段的方式,此时总用时 需要画时空图得到。
3.7

- 会发生阻塞
- 最大吞吐率为 ,处理 10 个任务时的实际吞吐率是 ,效率是
- 设置两个第 3 段,改进后,,吞吐率变为 , 效率变为
3.8
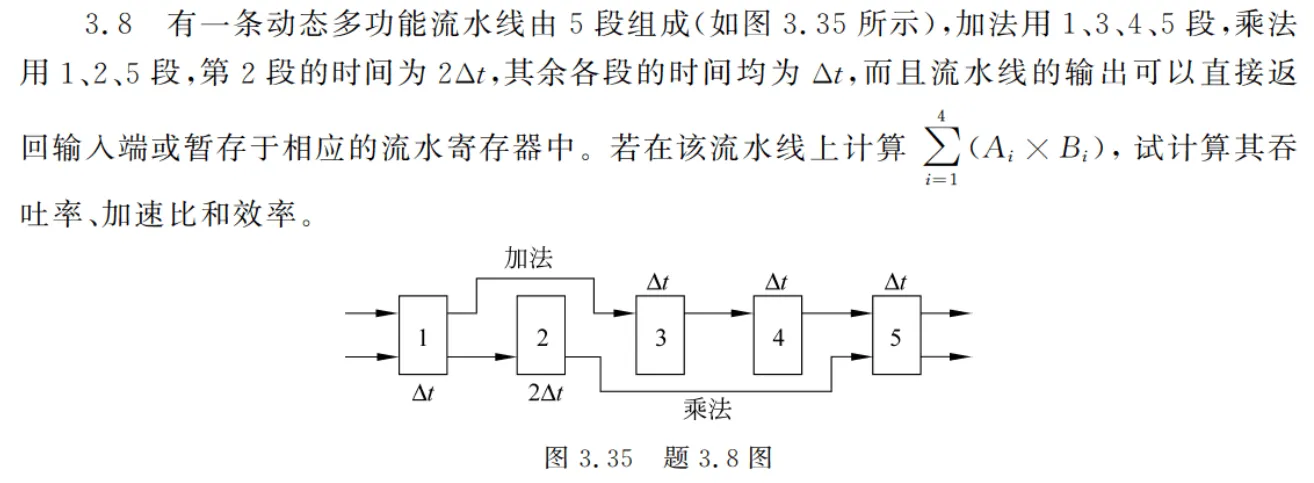
计算任务需要 4 次乘法,3 次加法,且加法操作需要至少两个乘法结果才能进行。 画时空图发现,先进行全部乘法操作,再进行加法操作所得到的就是最优结果。
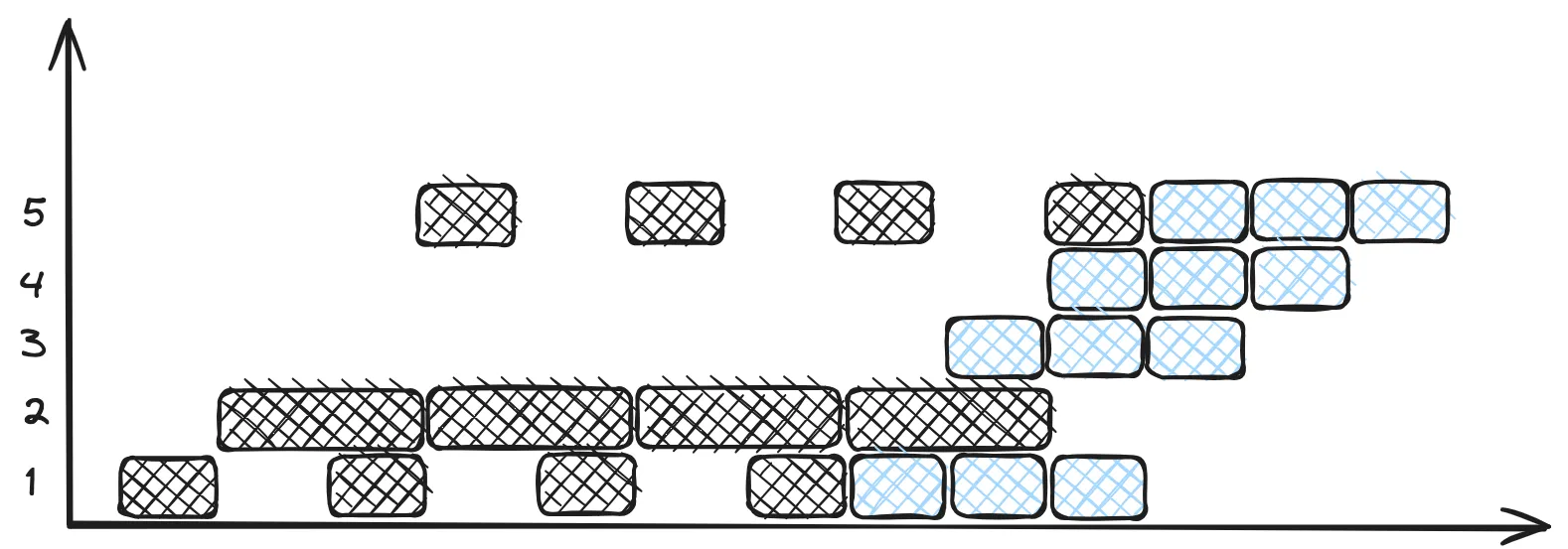
吞吐率为 7 / 13,加速比为 ,效率由阴影面积比总面积得到。
3.12

- 排空流水线策略,条件分支多 2 个时钟周期,其他多 1 个时钟周期,CPI = 1 + 20% * 2 + 5% = 1.45
- 预测分支成功策略,预测成功多 1 个时钟周期,预测失败多 2 个时钟周期, CPI = 1 + 20% * (60% + 40% * 2) + 5% = 1.33
- 预测分支失败策略,预测成功无额外时钟周期,预测失败多 2 个时钟周期, CPI = 1 + 20% * (60% * 2 + 40% * 0) + 5% = 1.29